Medical AI has no shortage of impressive papers—what it lacks is a reliable playbook for making models behave in the messy reality of clinics. In a recent episode of NEJM AI Ground Rounds, physician-scientist Dr. Lily Peng—known for early, influential work using deep learning to detect diabetic retinopathy in retinal fundus photos and for later evaluations in India and Thailand—walks listeners through the hard part: translating “it works” into “it works here, for these patients, with this workflow, every day.”
Peng’s perspective matters because it spans the full arc that most teams only see in fragments: model ideation, publication, validation beyond the original dataset, and the operational realities of deployment. As reported by NEJM AI Ground Rounds, her experience includes the landmark 2016 retinopathy study and subsequent real-world assessments of deep learning systems in different health systems—exactly the kind of work that exposes why promising AI can stumble outside carefully curated benchmarks.
Why ophthalmology became a proving ground for clinical AI
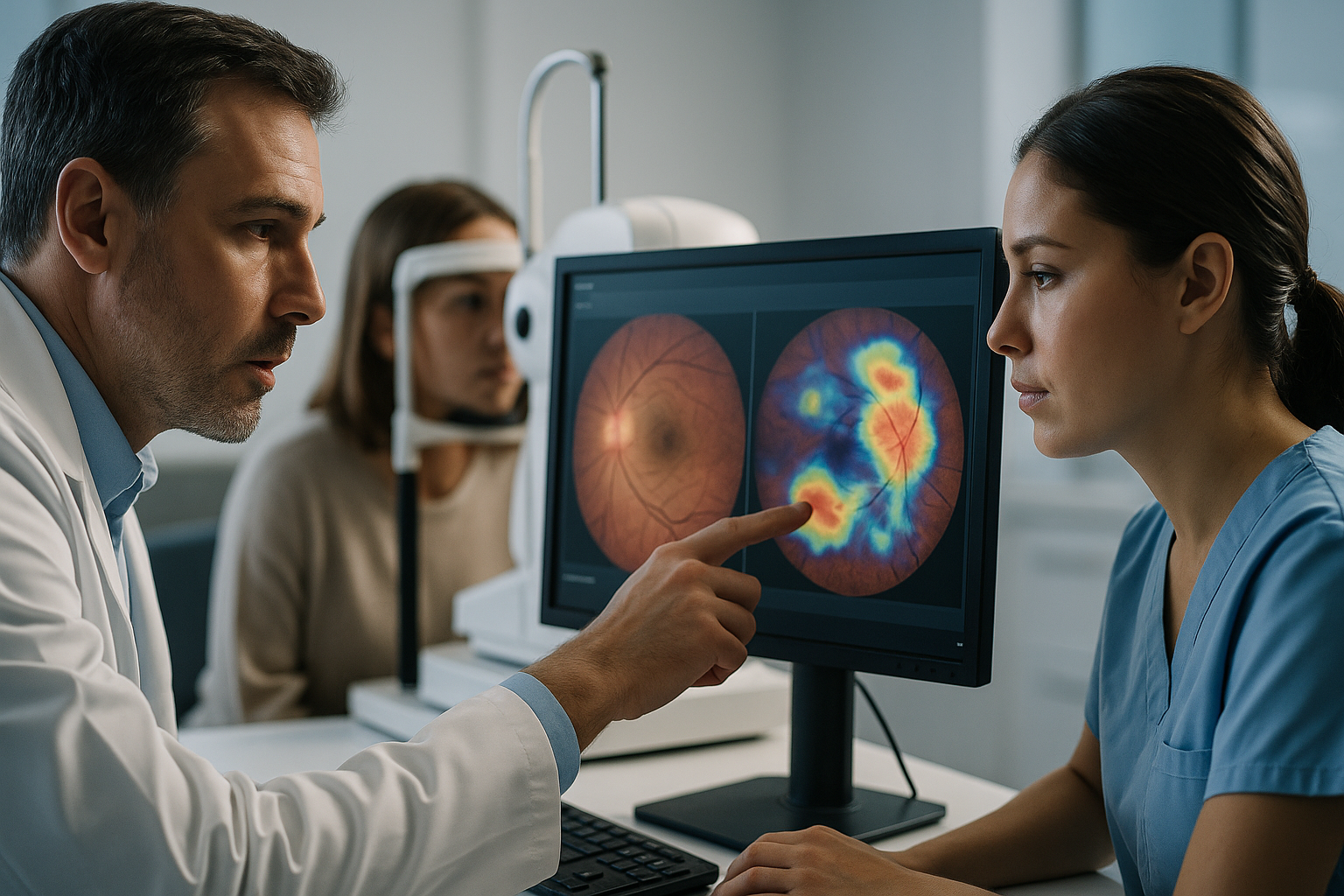
Ophthalmology is often described as “AI-ready,” and for good reason. Eye care generates high-volume imaging with relatively standardized acquisition (fundus photography, OCT), and conditions like diabetic retinopathy have established grading frameworks. That combination makes the specialty a natural test bed for algorithmic triage: find disease early, refer appropriately, and prevent avoidable vision loss.
But the field’s AI friendliness can create a false sense of universality. A model trained on one set of cameras, clinics, and patient demographics may not generalize when lighting, pupil dilation practices, prevalence of disease, or image artifacts change. Peng’s work—particularly the emphasis on evaluation in India and Thailand, according to the podcast—underscores a truth that healthcare leaders are increasingly internalizing: clinical AI isn’t a product until it proves itself in the environments where it will be used.
The real-world gap: performance isn’t a single number
In research, performance is often summarized as a headline metric. In real care delivery, performance is a living system property. Sensitivity and specificity matter, but so do failure modes: What happens when images are ungradable? How often does the system defer? Who gets flagged for follow-up, and can the health system absorb the referrals? Does the AI increase screening throughput—or does it create new bottlenecks?
The deployment journey highlighted in NEJM AI Ground Rounds implicitly points to a broader lesson for the industry: external validation is not a checkbox. It’s an ongoing discipline that must account for distribution shifts, operational constraints, and the fact that “ground truth” itself can vary between graders, geographies, and clinical norms.
Implications for clinicians: AI changes work, not just decisions
For healthcare professionals, the key implication is that AI tools—especially those used for screening and triage—reshape workflows as much as they shape diagnoses. A retinopathy model isn’t merely an automated grader; it is a new actor in the care pathway. That means clinicians should ask questions that go beyond accuracy:
Workflow fit: Where does AI output land—EHR, image viewer, referral queue—and who is accountable for acting on it?
Escalation logic: When the model is uncertain or images are poor quality, what is the human fallback, and is it resourced?
Performance monitoring: Is there a plan to track drift, ungradable rates, and subgroup performance over time?
Clinical governance: Who owns the model’s change management—updates, revalidation, and communication to staff?
Peng’s experience, as discussed on the podcast, is a reminder that clinical adoption hinges on trust built through transparency, consistent behavior, and clear responsibility—not just promising ROC curves.
Implications for patients: access, equity, and the risk of uneven benefits
For patients, the upside of ophthalmic AI is straightforward: earlier detection, fewer missed cases, and expanded screening capacity—particularly in settings where specialists are scarce. A scalable screening tool can move diagnosis closer to primary care, pharmacies, mobile clinics, or community health programs.
The risk is that benefits accrue unevenly. If a model performs best on populations and imaging setups similar to its training data, some communities may experience higher false negatives (missed disease) or higher false positives (unnecessary anxiety and referrals). Real-world evaluations in diverse settings, like those Peng has been involved in according to NEJM AI Ground Rounds, are not just scientific rigor—they are equity work. The point isn’t merely to prove the model can travel; it’s to ensure patient safety and fairness when it does.
What this signals for the next wave of clinical AI
Peng’s career arc highlights where the market is heading: away from “build a model” and toward “run a model in a system.” That shift elevates capabilities that traditional AI development often undervalues—implementation science, human factors engineering, continuous quality monitoring, and pragmatic trial design.
In the next few years, the most credible vendors and health systems will likely differentiate on operational excellence: robust post-deployment surveillance, clear clinical governance, and evidence that models remain safe and useful as cameras change, populations evolve, and workflows shift. Ophthalmology may still be the template, but the lesson applies broadly—from radiology to dermatology to cardiology: the hard part isn’t getting AI to predict. It’s getting AI to reliably improve care.
Source: NEJM AI Ground Rounds, “Dr. Lily Peng: AI for Ophthalmology and the Challenges of AI in the Real World” (as reported by NEJM AI Ground Rounds): https://ai-podcast.nejm.org/e/dr-lily-peng-ai-for-ophthalmology-and-the-challenges-of-ai-in-the-real-world/